AutoTS#
Use DataRobot AutoTS to train time series challenger models on a dataset and establish a champion.
Under Construction
We are working on various enhancements to time series in drx.
We would love to incorporate contributions from the DataRobot community! If you think you can handle a part of this feature, please reach out to Marcus, Luke or Marshall.
Key functional aspects of AutoTS:
Prior to model training, time-series feature engineering (e.g. derivation of temporally lagged variables) will be automatically performed on the training data.
For non-stationary series, a differencing strategy may automatically be applied prior to training.
Datetime partitioning will be used for model evaluation and models can be evaluated across a forecast horizon of interest as well as across multiple backtests.
For certain model types, independent models will be automatically trained for each forecast horizon of interest.
The feature engineering, datetime partitioning, and forecast horizon capabilities of
AutoTS provide many opportunities for further user configuration and customization.
See the drx DRConfig class and it’s attributes to explore
the breadth of TS-related options.
As with the drx AutoML model, prediction and
deployment methods execute on the present champion model at the time
of calling. Training is performed within a new, automatically created DataRobot project.
Usage#
Train#
import pandas as pd
import datarobotx as drx
df = pd.read_csv('https://s3.amazonaws.com/datarobot_public_datasets/DR_Demo_Google_AdWords.csv')
train = df[df['Date']<='2017-10-20']
model = drx.AutoTSModel()
model.fit(train, target='SalesCount', datetime_partition_column='Date')
Train with additional configuration#
config = drx.DRConfig()
config.Partitioning.DateTime.autopilot_data_selection_method = 'rowCount'
config.Featurization.AutoTS.differencing_method = 'none'
model_2 = drx.AutoTSModel(feature_window=(-10, 0),
forecast_window=(1, 3),
name='My AutoTS project',
**config)
model_2.fit(train, target='SalesCount', datetime_partition_column='Date')
Predict#
DataRobot time-series models require multiple rows of historical data to make predictions. The number of historical rows required for predictions varies depending on the feature derivation window and differencing settings, see the DataRobot documentation for additional information.
forecast_point = '2017-11-25'
fdw_start = '2017-11-15'
filter_condition = (df['Date'] >= fdw_start) & (df['Date'] <= forecast_point)
test = df.loc[filter_condition]
predictions = model.predict(test)
Predict with additional configuration#
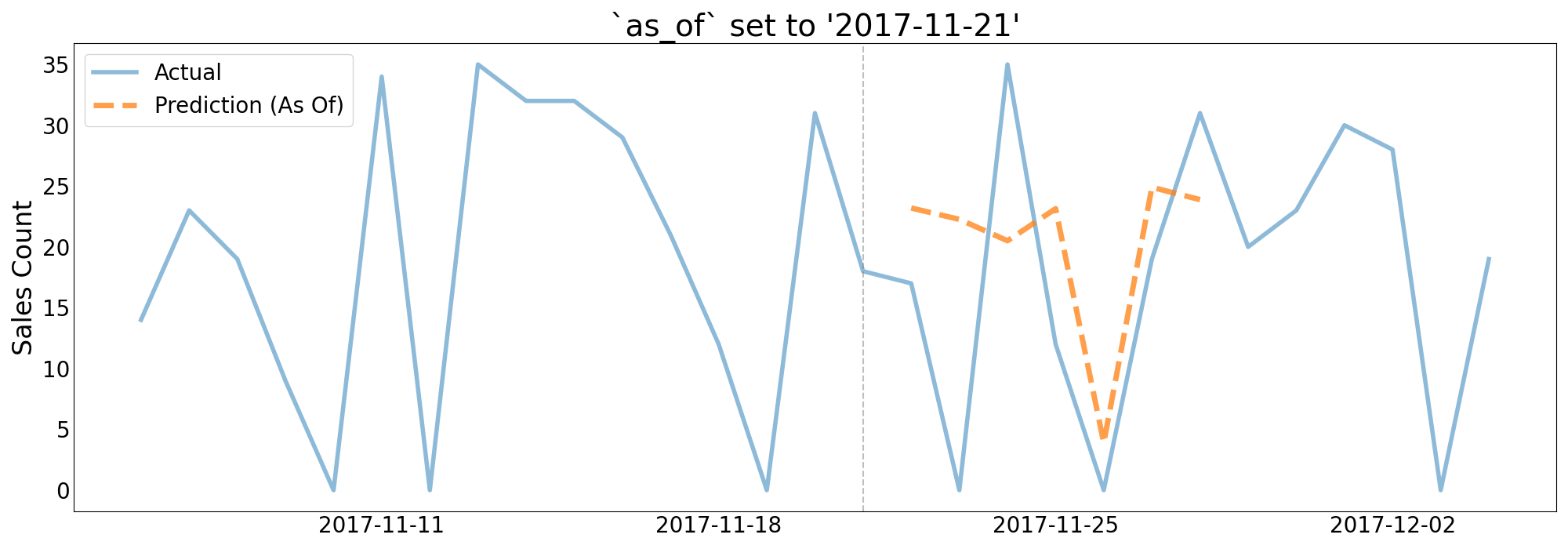
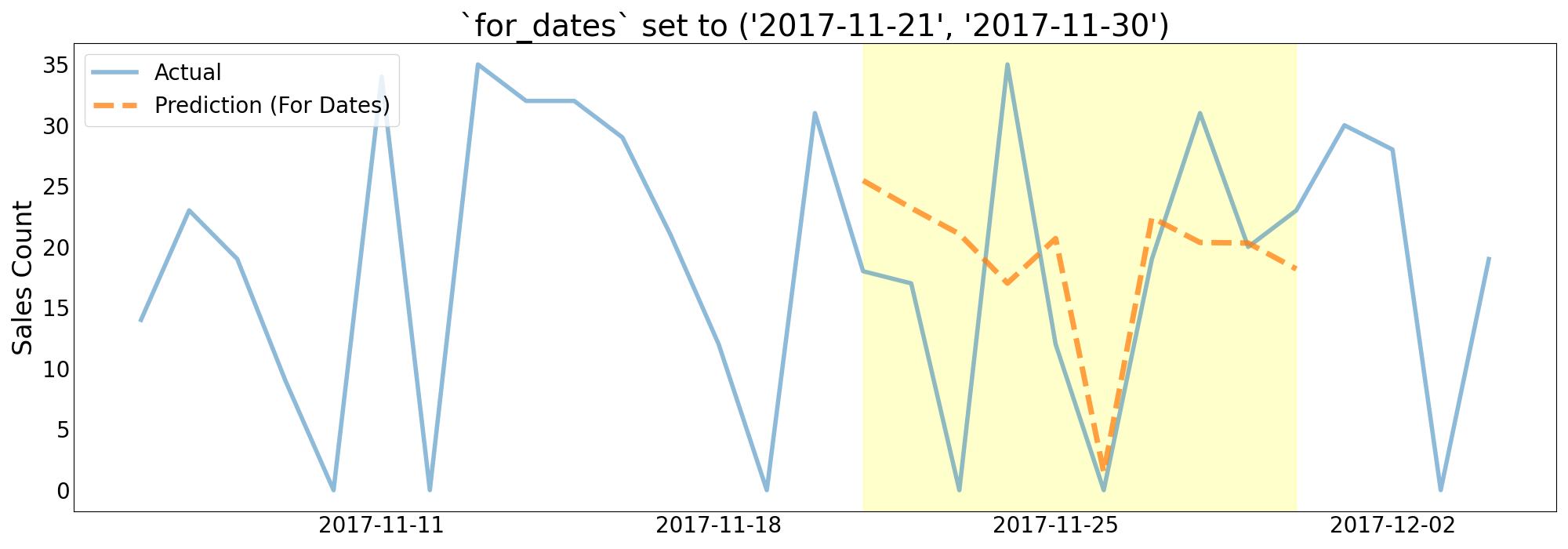
drx allows users to configure predictions using the as_of or for_dates keyword arguments.
Supplying the argument
as_ofsets the forecast point on which to make predictions. For example, if a model was trained to forecast 3-5 days out and the user supplies"03-01-2014"as theas_ofargument, the model will return predictions for["03-04-2014", "03-05-2014", "03-06-2014].Supplying
for_datesallows the forecast point to vary and just returns one prediction for each of the supplied dates. For example, iffor_datesare set to the range("03-01-2014", "03-03-2014)the model will return predictions for["03-01-2014", "03-02-2014", "03-03-2014"].
# Returns one prediction for each day from 2017-11-21 to 2017-11-30
predictions = model.predict(df, for_dates=("2017-11-21", "2017-11-30"))
# Returns one prediction for each day in forecast window as of 2017-11-21
predictions = model.predict(df, as_of="2017-11-21")
Predict - Special Cases#
drx will modify the uploaded dataset and post process the predictions returned when a user supplies as_of or for_dates arguments. Some examples of these modifications are:
Handling inconsistently formatted dates using
pd.to_datetimeAppending records to the uploaded dataset forecasts are requested beyond the range of the uploaded data.
Using the modal value of a feature to infer its future values when known in advance features are missing from the dataset.
Filtering the predictions returned from the platform to the smallest possible forecast distance for each timestamp.
Sometimes, this behavior can be undesirable. For example, in cold start time series problems, drx might not be able to make inferences on the dataset and will raise an error. In other cases, throwing an error when supplied with an inconsistent date format may be preferred (e.g. handling 1/10/2016 may mean January 10 or October 1). In cases like these, a user may prefer to use the “classic” time series parameters. As long as a user does not supply as_of or for_dates arguments, drx will not perform any additional pre or post-processing on the dataset or predictions.
# Return one prediction for each day in the range for each forecast point in the forecast window.
predictions = model.predict(
df, predictions_start_date="2017-11-21", predictions_end_date="2017-11-30"
)
# Returns one prediction for each day in forecast window as of 2017-11-21
predictions = model.predict(df, forecast_point="2017-11-21")
Deploy#
deployment = model.deploy()
Unsupervised Learning#
drx AutoTSModels also support unsupervised learning for both anomaly detection and clustering.
Anomaly Detection#
If a user does not pass a target value, drx will train an anomaly detection model by default.
df = pd.read_csv(
"https://s3.amazonaws.com/datarobot_public_datasets/TimeSeriesAnomalyDetection/device_failure/device_failure_train.csv"
)
ts_anomaly_model = drx.AutoTSModel()
ts_anomaly_model.fit(df, datetime_partition_column='date', multiseries_id_columns='device')
Clustering#
Time series clustering models require the user to disable the holdout set and to explicitly flag the project type as clustering.
df = pd.read_csv("https://s3.amazonaws.com/datarobot_public_datasets/TimeSeriesClustering/acme_234series.csv")
cluster_data = df[['Date', 'seriesID', 'SalesQty']]
ts_cluster_model = drx.AutoTSModel()
# Disabling the holdout dataset is required to run time series clustering projects
ts_cluster_model.set_params(
unsupervised_type='clustering',
disable_holdout=True
)
ts_cluster_model.fit(
cluster_data,
datetime_partition_column='Date',
multiseries_id_columns='seriesID'
)
API Reference#
|
Automated anomaly detection orchestrator. |
|
Automated clustering orchestrator. |
|
AutoTS orchestrator. |
|
DataRobot configuration. |
|
DataRobot ML Ops deployment. |